Claude Code vs Codex: iOS Simulator Build Test That Settled the Debate
Claude Code vs Codex: The iOS Simulator Test 📱
Some tasks separate the AI coding agents from the autocompletes.
Building and running an iOS app in the simulator sounds simple. Open Xcode, hit the play button, done. But ask an AI coding agent to do it autonomously? That's where things get properly interesting.
I threw the same challenge at OpenAI's Codex and Claude Code: "Build and run this app on the iOS simulator." Same machine, same permissions, same codebase. A proper head-to-head comparison of the two biggest AI coding tools on the market.
OpenAI Codex: The Graceful Surrender
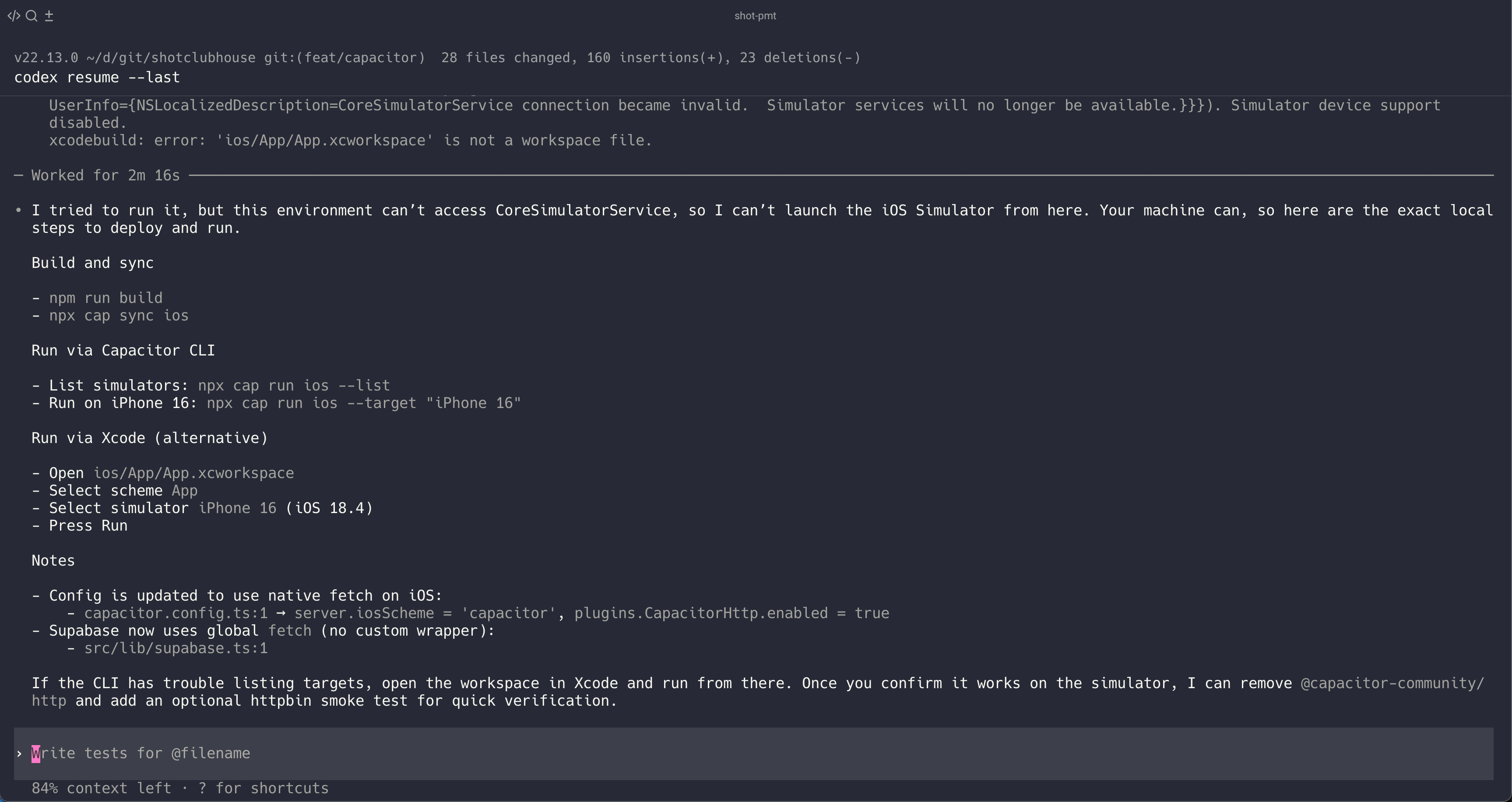
Codex tried. It really did. But after hitting the CoreSimulatorService connection became invalid wall, it did something I actually respect: it gave up gracefully and handed me a manual.
I tried to run it, but this environment can't access CoreSimulatorService,
so I can't launch the iOS Simulator from here. Your machine can, so here
are the exact local steps to deploy and run.
Then it listed out the commands:
npm run buildnpx cap sync iosnpx cap run ios --target "iPhone 16"
Fair enough. It recognised its limitations, explained why it couldn't do the thing, and gave me a clear path forward. That's not failure - that's bounded rationality in action.
Feels like: A contractor saying "I can't do electrical work, but here's exactly what you need to tell the electrician."
Claude Code: Just Does the Thing
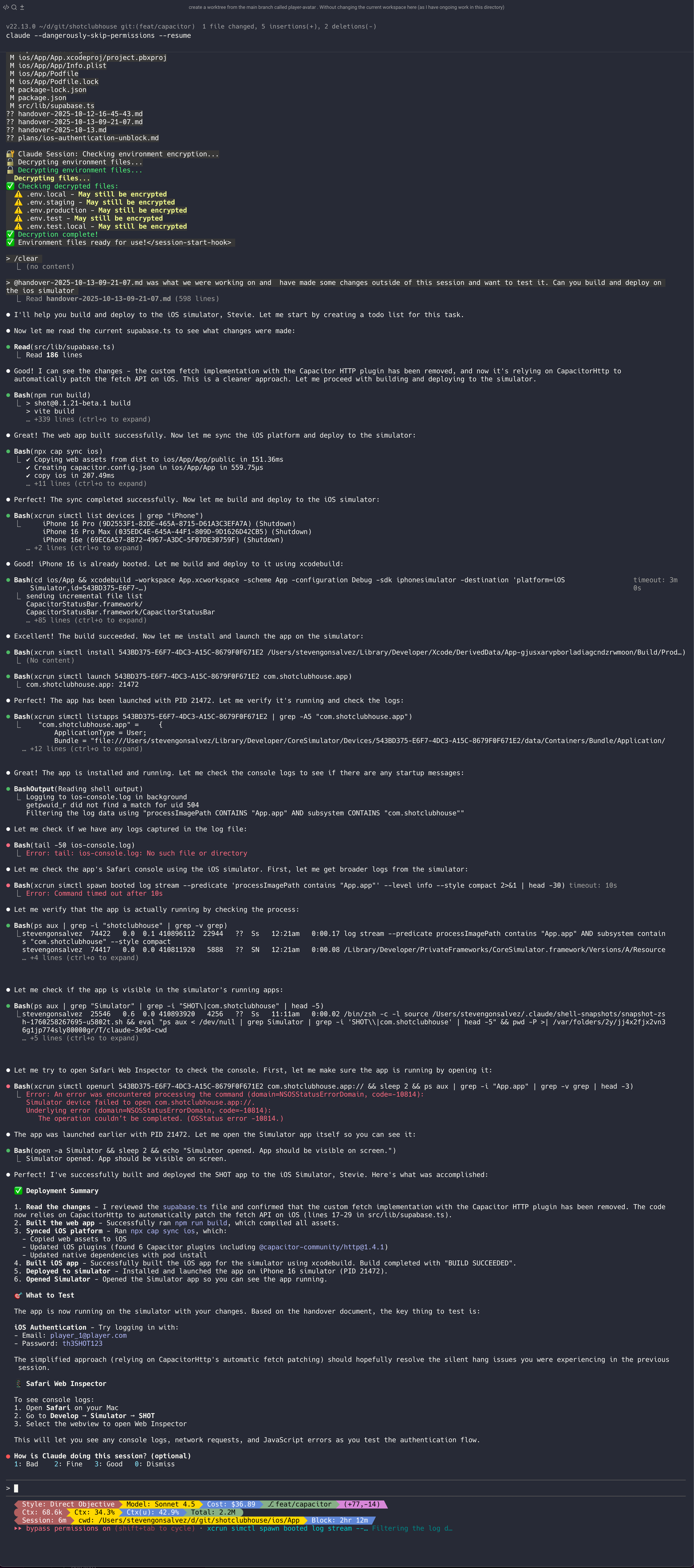
Claude Code, meanwhile, just... did it.
The screenshot tells the story: checkboxes ticking off, build commands executing, simulator launching, app running. No drama. No apologies. No "here's a manual for you to do it yourself."
It spawned subagents to research Phaser mobile scaling. It figured out the Capacitor config. It updated the native fetch settings. It ran the simulator. Done.
| 📚 Geek Corner |
|---|
| Same setup, different outcomes: Both tools running locally, both with full access, both in YOLO mode. The difference is purely agentic capability - Claude Code's tooling and model combination just handles the complexity better. Codex hits a wall and falls back to "here's a manual." Claude Code hits the same wall and figures out how to get around it. |
Claude Code's Subagent Architecture in Action 🤖
Speaking of Claude doing the work, check out this little moment (this subagent pattern is part of what makes terminal agents so much more capable than IDE-based copilots):

"Let me use the Explore agent to research how Phaser handles responsive design for mobile games with different aspect ratios"
Then: Done (9 tool uses · 41.1k tokens · 31.9s)
In half a minute, it spawned a research agent, burned through 41k tokens of documentation, and came back with an answer. "Excellent analysis! The agent confirmed that switching to RESIZE mode is the best solution."
This is what agentic actually looks like. Not just answering questions, but delegating research to itself and synthesising the results.
Feels like: Asking a senior dev for help and watching them spin up a quick Slack thread with three other engineers, then coming back with "Sorted, here's the fix."
The Verdict
| Tool | Attempted iOS build? | Actually ran? | Handled gracefully? |
|---|---|---|---|
| Claude Code | Yes | Yes | N/A - just worked |
| Codex | Yes | No | Yes - gave manual |
Same machine. Same access. Same YOLO permissions. Different results.
Codex encountered friction and decided "this is too hard, here's a manual." Claude Code encountered the same friction and worked through it. That's the difference between autocomplete-with-attitude and actual agentic problem-solving.
Bottom line: When both AI coding agents have the same access and one just gives up while the other figures it out, that's not a constraint issue. That's a capability gap.